
























라인, 음성 신호처리 학회 ‘ICASSP 2023’서 논문 8편 채택






음성 인식 및 음성 합성 연구 성과 우수성 인정
채택 논문 8편 중 6편 라인이 주저자로 작성
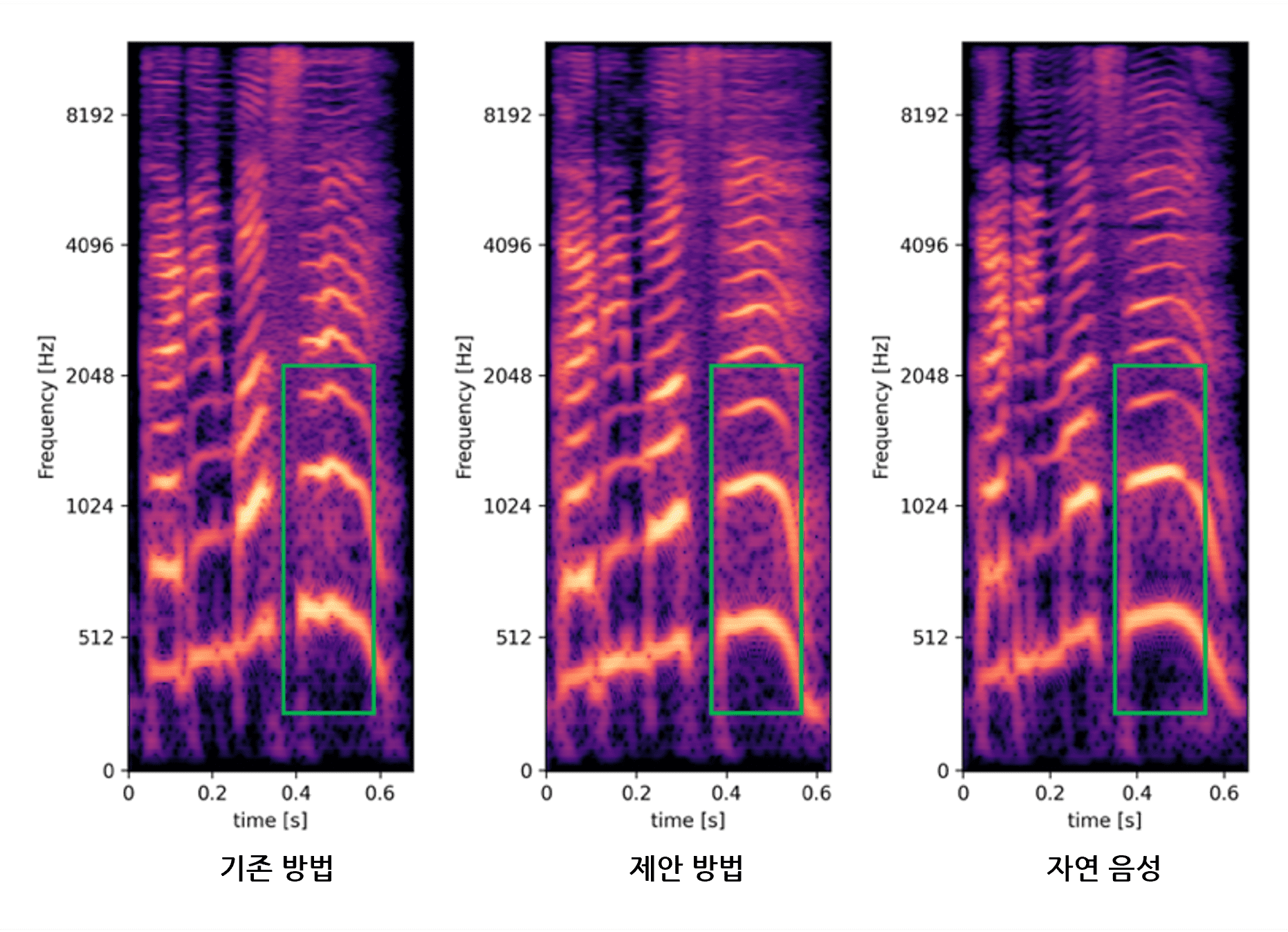
생성 음성 및 육성 음성의 멜 스펙트로그램. [사진=라인]
[서울경제TV=윤혜림기자] 라인이 세계 최대 규모의 음성·음향·신호처리 학술대회인 ICASSP 2023에서 논문 8편이 채택되었다고 14일 밝혔다.
올해로 48회차를 맞이하는 ICASSP(International Conference on Acoustics, Speech, and Signal Processing)는 국제전기전자협회 신호처리학회(IEEE Signal Processing Society)가 주최하는 음성·음향·신호처리 분야 내 세계 최대 규모의 국제학회이다.
채택된 논문 8편 중 6편은 라인이 주저자로, 해당 학회에 채택된 라인이 주저자인 논문 수는 지난해 3편에서 두 배 늘어나는 성과를 거두었다. 2편은 다른 저자와 공동 집필한 논문이며, 모두 학회 개최 기간인 6월 4일부터 10일 중 발표된다.
이번 ICASSP 2023에서 채택된 논문4에는 감정 음성 합성 시 텍스트에서 음성 파형으로 변환하는 과정에서 음성 피치 정보(음성 높이)를 이용하는 엔드투엔드(End-to-End) 모델에 관한 제안이 소개되었다. 기존 모델은 보다 풍부한 표현을 필요로 하는 감정 음성 합성 시 자연스러운 음성을 합성하기 어려운 사례가 많았으나, 변환 과정을 단일 모델로 수행하는 엔드투엔드(End-to-End) 모델은 양질의 음성을 생성할 수 있다.
제안 방법에서는 감정 음성 합성 시 보다 중요한 피치 정보를 양(陽)으로 모델링했다. 이를 통해 생성 음성의 피치 정보를 보다 정확하게 표현할 수 있게 되어, 기존 방법으로는 생성이 어려웠던 피치가 극단적으로 높거나 낮은 발화에서도 보다 자연스럽고 안정된 결과를 얻을 수 있음을 입증했다.
또한, 논문5에서는 다수의 화자가 혼재된 음성을 분리하는 음원 분리 시 이미지 생성에도 활용되는 확산 모델을 이용하는 방식이 채택되었다. 머신러닝을 이용하는 기존의 음원 분리는 교사 데이터의 음성 분리도를 극대화하는 식별 모델을 이용하는 방식이 주류였으나, 분리도가 높은 음성이라도 인간이 듣기에는 부자연스러운 경우가 종종 있었다.
제안 방법에서는 이미지 생성에도 활용되는 생성 모델 중 하나인 확산 모델을 음원 분리에 활용함으로써 자연스러운 음성 생성을 실현했다. 확산 모델을 활용한 결과, 분리음의 왜곡이 줄어들어 인간의 지각 능력에 기반한 음성 품질 평가 지표(DNSMOS)에서 기존 방법을 상회했다.
라인은 AI 기술을 활용해 새로운 서비스를 창출하는 동시에 AI 기술 연구 개발 활동에도 적극 투자하고 있다. 특히 음성 처리 분야에서는 음성 인식 및 음성 합성 기술을 중심으로 여러 저명한 학회에서 영향력 있는 연구 성과를 발표한 바 있다.
라인은 앞으로도 AI 기술 기초 연구를 적극 추진해 기존 서비스의 품질 향상은 물론 새로운 기능과 서비스 창출에 노력을 기울일 예정이다./grace_rim@sedaily.com
[ⓒ 서울경제TV(www.sentv.co.kr), 무단 전재 및 재배포 금지]



주요뉴스
주간 TOP뉴스
- 1미나 “전화받어” 챌린지, 민원 응대 공무원 보호 캠페인까지 확산
- 2“빌 게이츠까지?” 美 열풍 피클볼…패션업계도 ‘주목’
- 3전북개발공사 “익산 부송 데시앙 책임지고 준공”
- 4[이슈플러스] “외국인 관광객 회복”…유통업계 기대감↑
- 5"전남권 의대유치 공모는 부당" 순천대 불참에 꼬이는 전남도
- 6카페051, 5월 1일 전국 가맹점 아메리카노 무료 행사 진행
- 7그로쓰리서치"클리오, 인디브랜드 최강자…올해 최대 실적 전망"
- 8“에스파와 함께”…미쟝센, ‘퍼펙트세럼’ 신규 광고 온에어
- 9사모펀드發 상폐추진 봇물…‘커넥트웨이브’도 증시 떠난다
- 10쿠팡, 1분기 국내 이커머스 관심도 1위 … G마켓·11번가 뒤이어
공지사항
더보기
핫클립
-
- 지수상승하면 우량주, 혼조세면 개별주, 하락하면 관망 평택촌놈의 정석투자 2019-03-26 (화) 방송
- 메타버스와 교육이 합쳐진다? 웅진씽크빅 지금이 매수 타이밍!│ 매매전력(웅진씽크빅,교육주,윤석열관련주) 마감임박! 60분의 승부 2021-11-12 (금) 방송
- [내일의 BOOM] 탄소감축 = 원전? 달리는 말 '세보엠이씨' 탑승 전략은? │ 매매전략 (세보엠이씨,원전주,종가베팅) 오늘장 내일장 2021-11-12 (금) 방송
- 2월 25일이 반등 고점은 확실, 이제는 하락 속도의 문제 평택촌놈의 정석투자 2019-03-26 (화) 방송
이 시각 이후 방송
-
11:50정오의 텐베거
생방송 김윤선 PD 조민재 MC
-
12:5013시 투자스쿨
생방송 김보민 PD 문다현 MC
-
13:50오늘장 내일장 1부
생방송 유혜진 PD 백선혜 MC
-
14:50오늘장 내일장 2부
생방송 유혜진 PD 백선혜 MC
-
15:50주식포맨
생방송 최민호 PD 이정원 MC
오늘의 날씨
2024-05-03(금) 03:00마포구 상암동13.0℃
강수확률 0%